I'am Industrial Engineer.
With a solid foundation in Industrial Engineering and a passion for data analysis, I have substantial experience in developing data-driven solutions. My advanced programming skills and statistical knowledge enable me to derive meaningful insights from large datasets. My analytical mindset allows me to effectively visualize data and generate innovative solutions. I regularly share my projects on GitHub and participate in technology discussions. My background in Industrial Engineering provides me with a systematic and efficiency-focused approach to data processes.


Projects
You can find detailed descriptions of completed projects and the technologies used here.


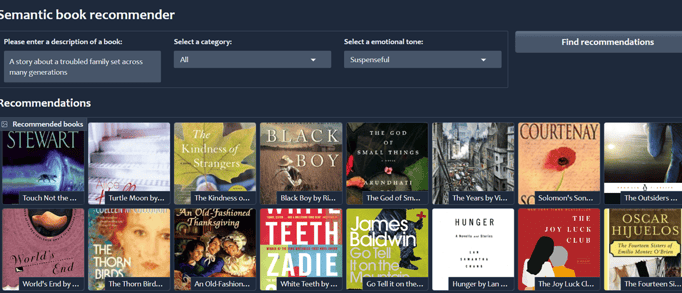
Project 1:Semantic Book Recommendation
This project focuses on Text-to-Speech (TTS) analysis—the process of converting written text into spoken language using deep learning and TTS technologies. The analysis covers various aspects such as the quality, accuracy, naturalness, and intelligibility of the generated speech. It also evaluates linguistic features including pronunciation, prosody (intonation, stress, rhythm), and emotion.


Project 3: RAG Application with Gemini API
Project 4: Olympic Games
This project demonstrates how to build a Retrieval Augmented Generation (RAG) chatbot using the Google Gemini API and the LangChain framework. The chatbot leverages document retrieval to provide accurate, context-aware, and natural conversational experiences.
Project 2 : Voice Over Application
This project is a Book Recommendation System that suggests books based on user preferences and book metadata. It uses content-based filtering, vector search, text classification, and sentiment analysis techniques to generate intelligent recommendations. The system is built with Python and deployed using Gradio for a clean and interactive web interface.
Link:https://github.com/elifkeskin/book-recommender/tree/master
This project analyzes over a century of Olympic Games data, spanning from 1896 to 2016. The Olympics is the most prestigious event in the life of athletes and is celebrated worldwide. The dataset provides a comprehensive view of athletes, events, and medal distributions across different years, sports, and countries.
The analysis was implemented on Databricks using PySpark and SQL, enabling scalable data processing and advanced analytics.




Project 5: Gezinomi Rule-Based Classification
Gezinomi aims to segment customers and predict potential revenue based on sales features using rule-based classification. The goal is to estimate the average revenue a prospective customer can generate, considering factors like destination, hotel concept, and seasonality.
For example, the company wants to determine the average revenue from customers booking all-inclusive hotels in Antalya during peak seasons.
Project 6: Fashion MNIST Classification
This project utilizes the Fashion MNIST dataset, which consists of 70,000 black and white images of clothing items categorized into 10 different classes. The goal is to build a deep learning model that can accurately classify these images into their respective categories.
To correctly classify images into 10 different types of clothing categories using deep learning techniques


Project 7: Web Scraping with Beautiful Soup & Selenium
A company that sells books online, It was seen that it had low sales in the “Non-Fiction” and "Travel" categories.For this reason, it is allowed the rival company for the web scraping.
"https://books.toscrape.com/" in the "Travel" and "Nonfiction" category from the website taking information about books and analyzing competitors and prices needs to do.
Goal:It is our duty to identify each book in these categories, go to the detail pages and view some of the contents there.


Project 7: Bank Customer Churn Prediction
This project aims to predict whether a bank customer will leave the bank (churn) or continue as a customer, using machine learning classification techniques. The analysis is performed on a real-world bank dataset and follows a typical data science workflow, including data preprocessing, exploratory data analysis, feature engineering, model building, evaluation, and interpretation.
Banks lose significant revenue when customers close their accounts. Early identification of customers likely to churn enables the bank to take proactive retention actions.
Goal:Build a predictive model that classifies customers as "churned" or "retained" based on their demographic and transactional features.